本次采集主要是采集某个头条号的文章。比如这个 http://www.toutiao.com/c/user/5803790269/#mid=5937891416
1、分析请求地址
首先我们进入页面,然后往下拉,就会自动加载更多的文章。这个过程发送ajax请求,分析发出的请求就行了。如下图:
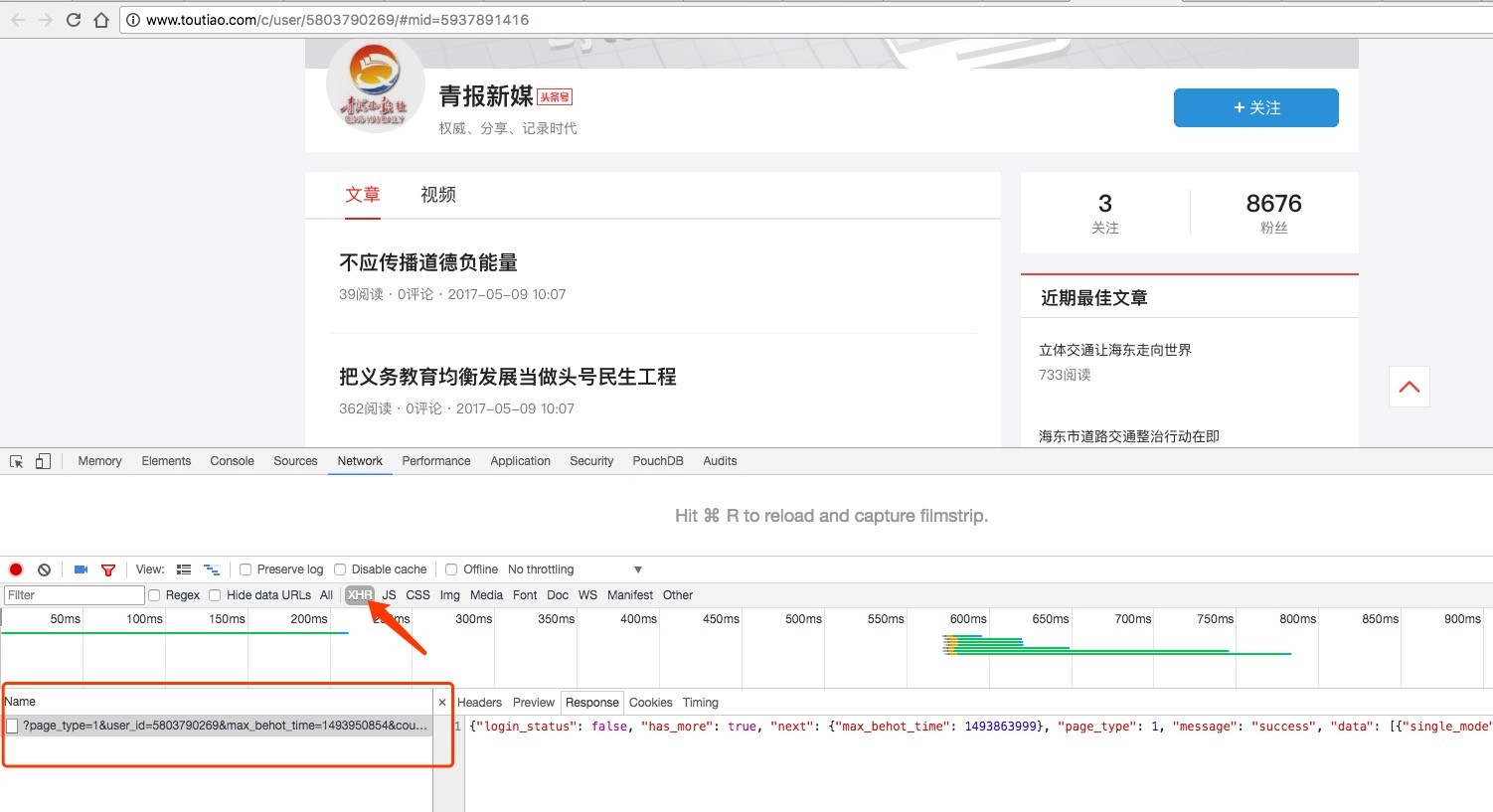
发出的请求是这样:http://www.toutiao.com/search_content/?offset=60&format=json&keyword=%E6%B0%B4%E5%88%A9&autoload=true&count=20&cur_tab=1
观察可见,
count=20 有可能就是控制一次请求几条的
offset=60就是从第几条查询。
弄明白这两个参数之后,我们可以这样调整:
http://www.toutiao.com/search_content/?offset=0&format=json&keyword=%E6%B0%B4%E5%88%A9&autoload=true&count=200&cur_tab=1
把offset参数设置成0,count参数设置成200,意思就是请求前200条。
当然,这些都是猜测的,没有人会告诉你这些参数具体的含义,得靠你聪明的大脑去猜测,去验证。
在本例中,我还猜测 format=json 参数的意思就是返回json格式的数据,不信你可以把这个参数去掉。有些字段会返回html的格式。
现在知道了请求地址,下一步写规则了
2、起始地址设置:
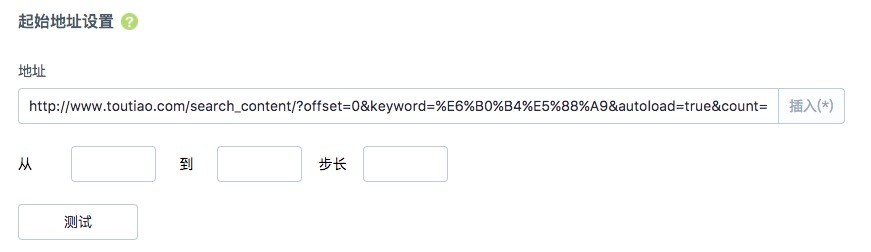
这里我们不按照分页采集,我们只采集每个公众号前200条的文章数据。然后每次自动采集更新就行了。所以这里直接填
http://www.toutiao.com/search_content/?offset=0&format=json&keyword=%E6%B0%B4%E5%88%A9&autoload=true&count=200&cur_tab=1
3、列表设置:
现在我们需要从列表地址里面构造文章详细url,随便点一篇文章,地址是
http://www.toutiao.com/item/6416097012231438849/
他会自动跳转到
http://www.toutiao.com/i6416097012231438849/
所以,我们只需要获取到6416097012231438849就可以了
然后我们分析从哪取这个id
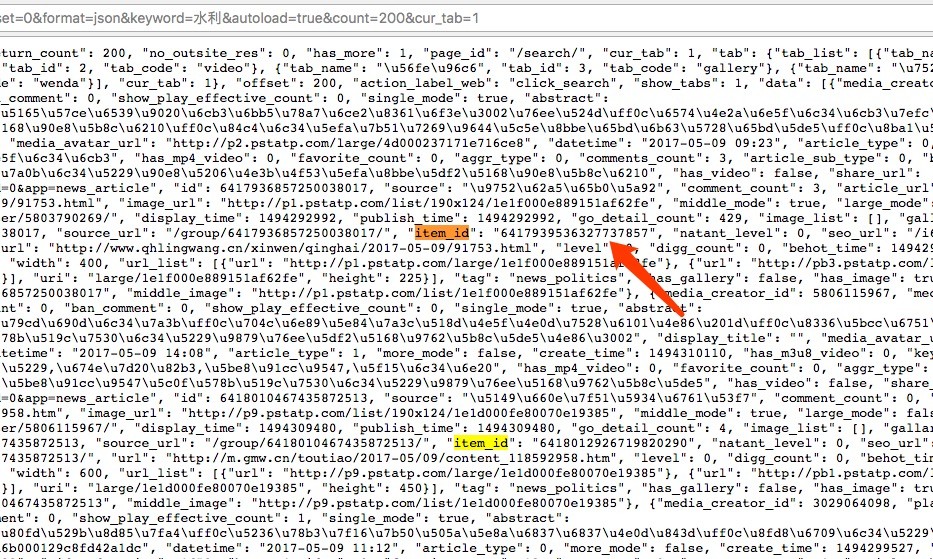
如图,他放在item_id这个字段里面。
规则
"item_id": "[data]",
如下图:
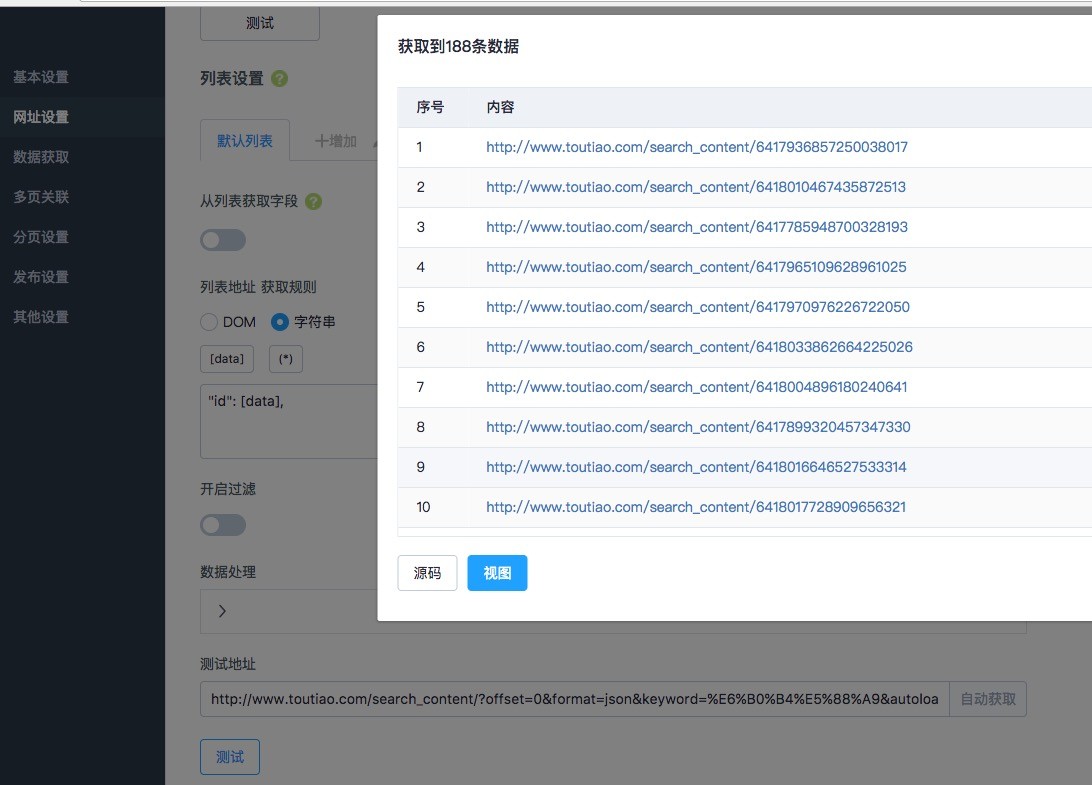
可以看到获取到id了,但是采集器自动补全成地址来了。现在我们需要把
http://www.toutiao.com/search_content/6417965109628961025
替换成
http://www.toutiao.com/item/6417965109628961025/
这个好办。
替换规则:
把
http://www.toutiao.com/search_content/{1}
替换成
http://www.toutiao.com/item/{1}
现在地址就正确了。
5、获取标题、内容
这个就很简单了,不懂可以看文档。
或者自己下载本例子的规则参考一下。
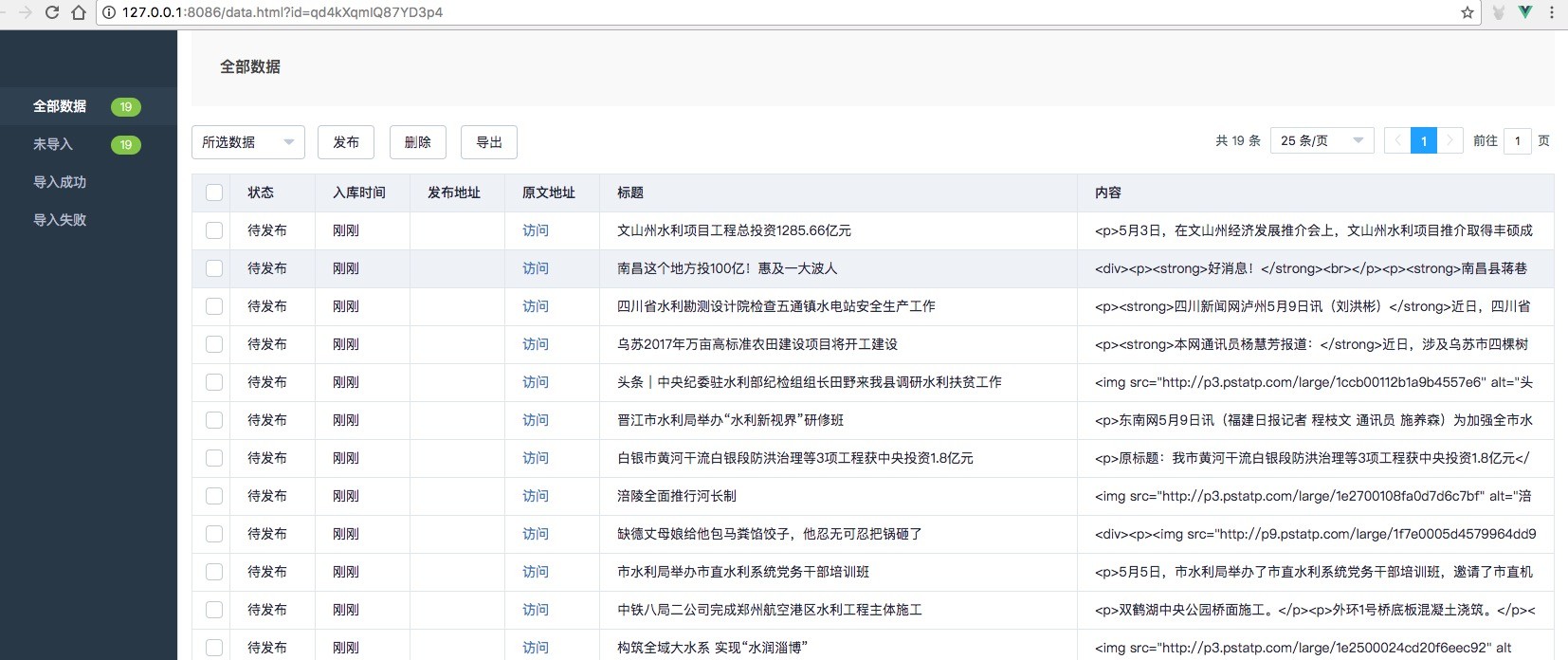
6、采集效果
采集的效果如下:
规则下载:
http://ww1.dxcer.com/%E9%87%87%E9%9B%86%E4%BB%8A%E6%97%A5%E5%A4%B4%E6%9D%A1%E8%87%AA%E5%AA%92%E4%BD%93%E5%8F%B7%E6%96%87%E7%AB%A0.dxc